 ZES – Center for Emergent-law-based Statistics
ZES – Center for Emergent-law-based Statistics
Searching for patterns that were always true in the past in order to predict the future.
Emergent-law-based Statistics is a completely new approach to data analysis that is based on a purely empirical solution of the so called “epistemological induction problem”.
On the basis of this approach members of the ZES have developed algorithms that have the following two main characteristics:
-
They make predictions that reach at least the prediction accuracy of state of the art Machine-Learning-Algorithms but are perfectly intuitive.
-
They compile databases that contain objectively true empirical knowledge. It is important to realize that any statements derived from this knowledge cannot contradict each other.
Knowledge Nets - Creation of Knowledge
Resulting Solutions
Using emergent-law-based Statistics allows applications that are (in our assessment) not possible with probability based statistics.
KnowledgeBases
Because in probability based statistics it is always possible to make probability-statements about the same future observations (i.e. make predictions) on basis of different probabilistic theories (or methods) that cannot be true at the same time.
So as an example, we can use lots of sets of probabilistic assumptions and an infinity of estimation methods and surely claim that the probability of rain tomorrow is 0.4, 0.5 or any other probability value. At the same time it is impossible to prove one of the claims or theories definitively wrong.
So it seems to be impossible to collect empirical stochastic knowledge in a Database. In our reasoning there is no stochastic empirical knowledge and a database containing empirical results that are based on stochastic models could include an infinite number of conflicting statements.
One of the major advantages of emergent-law-based statistics therefore is the fact that emergent laws and the simple prediction rule “predict that a pattern that always was true in the past also will become true the next time” cannot result in conflicting predictions. So it becomes possible to collect consistent empirical knowledge in form of emergent laws in databases.
See the power of the resulting KnowledgeBases in the following example:
(Click on the image for fullscreen.)
Learning Systems
Because emergent-law-based statistics makes definitively falsifiable predictions, it becomes possible to evaluate the laws stored in a KnowledgeBase continuously if the predictions are compared to real-time measured data.
This leads to a system that – at every point in time – has knowledge about “what was always true until now”.
At each point in time each law in the KnowledgeBase of a Learning System can be falsified by measurements and the system is learning continuously and the resulting set of surviving laws reflects the actual state of knowledge.
The following graph shows the structure of a Learning System:
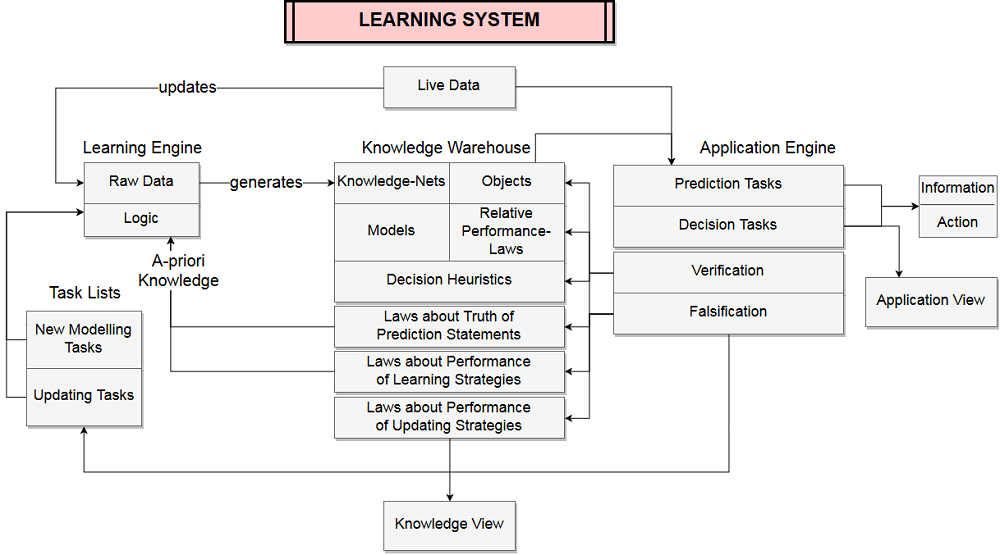
An Example of a Learning System is discussed in the following text.
More Thorough Discussion and Presentation of our Approach
Notebooks and Papers
Notebooks
In this section we show preliminary results. Because our methods lead to very fast progress and lots of results we want to publish some of them without taking too much care on formal restrictions like ortography and so on. Please excuse possible errors in advance.
Papers
Papers provide further information with a more detailed explanation of our approach.